Licht ins Dunkle der AI Begrifflichkeiten
Im vergangenen Jahr haben sich viele Themen um AI (zu deutsch: künstliche Intelligenz) und deren Implikationen gedreht. Fast im Zusammenhang mit jeder Branche und jedem Bereich konnte man Schlagwörter hören, die damit zusammenhängen. Ganz einfach ist es allerdings nicht zu durchschauen, wie die einzelnen Technologien zusammenhängen und die einzelnen Begriffe zueinander stehen. Um ein bisschen Licht ins Dunkel zu bringen hier nun also ein kurzer Überblick über das Themengebiet, in der Hoffnung für etwas mehr Verständnis zu sorgen.
AI ist nicht gleich AI
Es gibt bei künstlicher Intelligenz unterschiedliche Ausprägungen, deren Unterscheidung von großer Bedeutung ist, um das Forschungsfeld besser zu verstehen. Generell wird unterteilt in starke AI, schwache AI und künstliche Superintelligenz (auf englisch auch oft ANI = artificial narrow intelligence, AGI = artificial general intelligence und ASI = artificial super intelligence genannt). Erstere wird dafür gemacht, eine Sache oder einen Anwendungsbereich zu meistern. Als klassischen Beispiele lassen sich hier Schachcomputer, Bremsassistenten, Schrifterkennung, die Apps am Smartphone, aber auch Servicebots nennen. Diese Anwendungen können eine Aufgabe gut meistern, echte Intelligenz liegt ihnen aber natürlich nicht zu Grunde. Man könnte sagen, dass schwache AIs Intelligenz simulieren. Wie leicht zu erraten ist, ist dies derzeit jene Form, die für die meisten Probleme und Softwarelösungen zur Anwendung kommt.
Die starke AI ist in ihrer Anwendung nicht nur umfangreicher, sondern man vergleicht sie auf einem Level mit der menschlichen Intelligenz. Diese AIs können alle intellektuellen Aufgaben erfüllen, die auch ein Mensch erfüllen kann. Sie sind dabei nicht auf ein Aufgabengebiet beschränkt, sondern sind der menschlichen Intelligenz nachempfunden und können somit auch Dinge wie abstraktes Denken, Probleme lösen, komplexe Ideen erfassen und aus Erfahrungen lernen – um nur einige zu nennen. Wie zu erwarten ist, ist es um einiges schwieriger eine starke Intelligenz zu bauen, als eine schwache AI zu kreieren.
Die Implikationen von starken AIs reichen dabei auch stark in den philosophischen Bereich, empfinden doch manche Forscherinnen und Forscher, dass diese Form der künstlichen Intelligenz den Menschen früher oder später abschaffen könnte.
Die dritte Form, und somit auch Krönung, von AIs ist die künstliche Superintelligenz. Sie ist jene Ausprägung vor der die Welt der Forschung abwechselnd warnend den Zeigefinger hebt und mit der sie doch als potentielle Heilerlösung liebäugelt. Die ASI ist die Weiterentwicklung der starken AI, jedoch übertrifft sie den Menschen in allen Disziplinen und reicht somit von „ein bisschen klüger, als der klügste Mensch“ zu „milliardenmal klüger, als der klügste Mensch“. Die Auswirkungen einer solchen Maschine bzw. Technologie sind in Wahrheit nicht vorstellbar. In diesem Zusammenhang spricht man auch gerne von der (technischen) Singularität. Dies entspricht einem Ereignishorizont, über den wir nicht hinaussehen können, von dem wir nicht wissen was danach (nach der Singularität) passieren wird, und somit keine Aussagen über die Zukunft treffen können, da die technische Entwicklung sich dermaßen rasant beschleunigt, dass eine Vorhersage unmöglich wird.
Formen und Lernsysteme
Natürlich stellen sich nach der Einteilung der AIs noch viele grundlegende Fragen aus angrenzenden Themengebieten. Z.B. Wie passt Machine Learning in diesen Kontext und was ist hierbei der Unterschied zu Deep Learning? Und was sind eigentlich neuronale Netze?
Beim Machine Learning (bzw. maschinellen Lernen) geht es darum, dass eine Maschine Muster und Gesetzmäßigkeiten in Daten erkennt. Dies kann nur dadurch erfolgen, dass sie vorher mit (einem relativ großen Set) an Beispieldaten trainiert worden ist. Nur so kann das System auch mit unbekannten Daten etwas anfangen. Eine der klassischen Beschreibungen für Machine Learning ist folgende:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P improves with experience E.
– Tom M. Mitchell, Machine Learning, 1997
Sprich: je öfter ein Task durchgeführt wird und je größer somit der Erfahrungsschatz wird, desto besser sollte die trainierte Aufgabe ausgeführt werden können.
Beim Machine Learning wird gerne unterschieden in:
- Supervised Learning (überwachtes Lernen): Hierbei geht es darum eine Eingabe auf eine bestimmte Ausgabe zu mappen. Dies kann z.B. dazu verwendet werden Tiere zu klassifizieren. In diesem Fall wäre die Aufgabe also die Maschine zu trainieren, dass sie z.B. Bilder einteilen kann in: Hund, Katze, Bär, etc. und es somit eine definierte Ausgabe gibt – es muss am Ende jeder Datensatz einem Tier zugewiesen sein.
- Unsupervised Learning (nicht überwachtes Lernen): Bei dieser Variante gibt es eine klare Eingabe, aber keine definierte Ausgabe – man weiß also noch nicht genau wonach man in den Daten sucht. Es werden in diesem Fall auch keine Klassifizierungen sondern Clusterungen und Assoziationen vorgenommen. Z.B. können aus einem Datenset Kundinnen und Kunden mit ähnlichem Kaufverhalten zusammengefasst werden oder das klassische „Kundinnen und Kunden die nach X gesucht haben, haben auch nach Y“ gesucht. Diese Art des Lernens eignet sich besonders dann, wenn man an seine Daten explorativ herangehen möchte.
- Reinforcement Learning (Bestärkendes Lernen): Hier lernt das System durch die Interaktion mit einer Umwelt. Diese Art des Lernens bestärkt „gute“ Entscheidungen und bestraft „schlechte“ Entscheidungen. Ziel ist es die akkumulierte Belohnung, die das System für gute Entscheidungen erhält zu maximieren und eine Strategie zu entwickeln, wie zukünftige Entscheidungen besser getroffen werden können. Von der Idee entspricht dieses Modell sehr stark jenem des menschlichen Lernmodells.
Für die Arten des Machine Learnings gibt es viele unterschiedliche Ansätze. Die beiden bekanntesten hierfür sind wohl die künstlichen neuronalen Netzwerke, welche der Biologie des neuronalen Netzes des (menschlichen) Gehirns nachempfunden ist und das Deep Learning, welches das neuronale Netz noch um zusätzliche „versteckte“ Schichten erweitert.
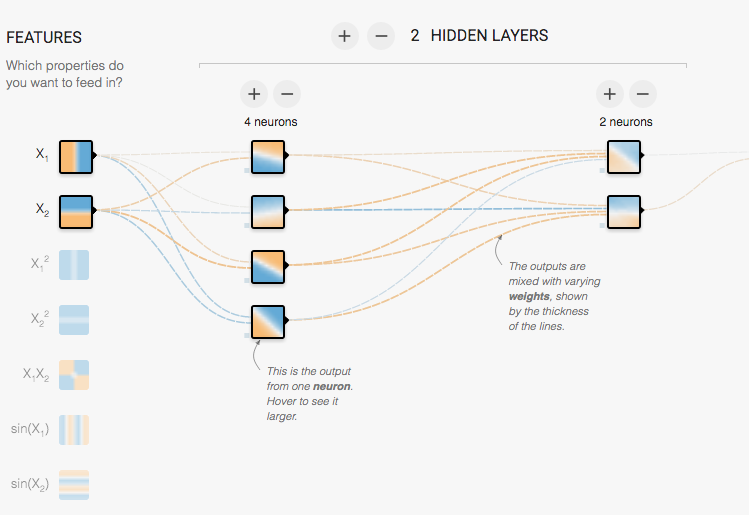
Beim neuronalen Netz handelt es sich um ein Forschungsgebiet, bei dem versucht wird, die Arbeitsweise des Gehirns nachzubilden. Da dies eine recht motivierte Angelegenheit ist, werden derzeit in erster Linie biologische Nervenzellen (Neuronen) untersucht und deren Konstrukte nachgebildet. Das Lernen der Maschine funktioniert dann dem Prinzip des menschlichen Lernens entsprechend: Die einzelnen Verbindungen werden gewichtet und „erstarken“ durch häufiges Verstärken bzw. Lernen der Verbindung. Wer das ganze gerne grafisch und interaktiv aufbereitet haben möchte, kann sich auf diesem Playground ansehen, wie ein künstliches neuronales Netz funktionieren kann.
Künstliche neuronale Netze haben auch in jüngerer Vergangenheit bereits für Schlagzeilen gesorgt: Z.B. AlphaGo, das Programm für das Brettspiel Go von Google Deep Mind schlug Anfang 2016 den weltweit besten Go Spieler Lee Sedol mit 4:1. Dabei brachte sich DeepMind selbst das Go spielen bei, in dem es Millionen von Spielen analysierte und mit einer Kombination aus unterschiedlichen Algorithmen aus dem Bereich des Deep Learnings und der neuronalen Netze arbeitete.
Neben diesem Beispiel basieren zudem viele Google Services auf neuronalen Netzen, besonders die Spracherkennung, aber auch Google Translate, welches im September einen neuen Algorithmus erhalten hat. Dieser bewirkt, dass Übersetzungen wesentlich effizienter und akkurater vorgenommen werden können, indem nun nicht mehr Wort für Wort übersetzt wird sondern bei jedem Wort der Rest des Satzes in den Übersetzungskontext miteinbezogen wird. Spannend ist an dieser Stelle zudem, dass sich die AI selbst eine Art interne Semantik erstellt hat, mit der sie Wörter in unterschiedlichen Sprachen verknüpft. Wenn Google Translate also z.B. von englisch nach koreanisch und von japanisch nach englisch übersetzen kann (aber nicht von koranisch nach japanisch) dann müsste die Applikation theoretisch einen Zwischenweg gehen, und Übersetzungen nach englisch vornehmen um dann in die jeweilige Sprache zu übersetzen. Dem ist aber tatsächlich nicht so. Die Anwendung hat selbstständig einen Algorithmus erstellt mit der es die Wörter in den unterschiedlichen Sprachen zuweist und übersetzt. Somit kann eine direkte Übersetzung von einer Sprache in eine andere stattfinden, die eigentlich gar nicht unterstützt wird. Wie dies genau von statten gegangen ist, ist auch den Forscherinnen und Forschern noch nicht ganz klar.
Künstliche Intelligenz in seiner Vielfalt und Machine Learning als darunterliegendes Konzept werden uns in den nächsten Jahren vermehrt begleiten. Denn die Anwendungsbereiche sind vielfältig und stetig am Wachsen. Dabei ist unerheblich ob es sich dabei um die Vermarktung von Produkten, die Auswahl der optimalen Saatgutkombinationen, die Analyse von gesundheitlichen Risikofaktoren oder die Programmierung von NPC (non-player character) in Spielen handelt. Es werden in naher Zukunft noch viele spannende Anwendungen und Technologien auf uns zu kommen, die unser Leben bereichern und uns wahrscheinlich auch ein bisschen das Fürchten lehren werden.
Veröffentlicht am: 02.02.2017

Autorin
Bernadette Fellner
(Ehemalige Mitarbeiterin)
Als Projektmanagerin beschäftigte sich Bernadette Fellner vor allem mit sicherheitsrelevanten Themen. Auf Ihrer beruflichen Laufbahn hat sie bereits einige Stationen durchlaufen: Development, Usability Consulting und Design.
Wir haben noch mehr super interessante Blogartikel!